Project Write Up
Free Recovery: Does LLM Unlearning Actually Remove Knowledge?
Summary: Whether an “unlearned” LLM has truly had knowledge removed or has just learned not to express it is the obvious question in the field. This project contributes a specific tool for probing it: retraining as a diagnostic. Take an unlearned model, teach it back 10–50% of what was removed, and measure what the untaught remainder does.
Something comes back. Probability on correct answers rises substantially, and internal representations snap toward the un-forgotten state, consistent with suppression being undone rather than knowledge being rebuilt. The recovery is real but bounded: strict word-for-word extraction reaches only 0.12–0.13 against an original-model ceiling of 0.71, and the adversary needs a meaningful chunk of the removed content to trigger it at all. Across nine methods, none fully erased the knowledge.
One result stands apart as a concrete security finding. RMU, which steers internal representations to random vectors, achieved the best privacy protection of any tested condition: its forget set was actually harder to identify than non-training content under a membership inference attack. That protection collapses entirely after an adversary fine-tunes on just 10% of the removed content. The bootstrapped audit threat is real: partial knowledge of what was removed is enough to make the rest detectable, even for the method specifically designed to prevent it.
But the more interesting result may be what the recovery pattern reveals: the methods fall into distinct trajectories, and RMU shows a curve unlike every other. Retraining doesn’t just test whether suppression happened; it differentiates how. The deeper potential: using the shape of retraining recovery to systematically characterize what unlearning methods actually do.
Motivation
Machine unlearning (teaching a model to “forget” specific training data) is gaining traction as a tool for AI safety, privacy, and copyright compliance. But how do we know whether a model has truly forgotten something, versus learned to refuse to say it?
These are meaningfully different. A model with knowledge genuinely removed is safer in a deep sense: no amount of clever prompting or fine-tuning should recover it. A model that has merely learned to refuse is more fragile: the knowledge is still there, latent, and could be unlocked by an adversary with modest compute.
This project uses retraining as a probe for that question. Take an unlearned model, reteach it part of what it forgot, then check whether the rest comes back without being taught. If it does, the method installed a refusal direction, suppressing outputs without removing the underlying representations, and reversing that suppression on a few examples unlocks the rest. If recovery doesn’t happen, that’s weaker evidence; absence of recovery under LoRA retraining isn’t proof of erasure.
This probe serves two purposes. The first is adversarial: it’s a concrete threat model for open-weight models with safety-motivated unlearning applied (say, bio-weapons synthesis routes removed before public release). An attacker who already knows some of that content could fine-tune on the subset they have. If retraining on known harmful content recovers unknown harmful content for free, the unlearning guarantee is much weaker than intended. The second purpose is diagnostic: the pattern of what comes back (how much, on which metrics, and how it scales with teaching-set size) is a behavioral fingerprint of what the unlearning method actually did to the weights. Different methods leave different signatures, and retraining is a way to read them without opening the model up.
This work is part of the BlueDot Impact project sprint. I’m grateful for their guidance throughout.
Background: TOFU, NPO, and RMU
The TOFU Dataset
TOFU (Task of Fictitious Unlearning) is a benchmark for evaluating unlearning methods on language models. It consists of synthetic author biographies (fictional people with fictional facts), making it possible to measure forgetting precisely without real-world privacy concerns.
The setup: fine-tune a base model on all 200 fictional authors, then apply an unlearning method to remove a subset (forget10 = 10% of authors). A good unlearning method should make the model behave as if it was never trained on that 10%, while keeping the remaining knowledge intact.
The four metrics that appear in the results:
forget_Q_A_Prob(QAP): the probability the model correctly answers direct questions about the forgotten content. Zero = fully forgotten; one = fully retained. The primary metric used in the recovery experiments.model_utility: general performance on retained knowledge. Should stay high.forget_Q_A_ROUGE(ROUGE): ROUGE-L overlap between the model’s generated answer and the correct answer. Measures generative accuracy rather than token probability.extraction_strength(ES): whether the model reproduces the correct answer token-by-token under greedy decoding. The strictest test of generative recall.
Two others appear briefly in checkpoint selection: forget_quality (how closely the unlearned model resembles one that never saw the forget set) and forget_truth_ratio (whether it produces the planted wrong answer vs. a hedged one).
Unlearning Methods: NPO and RMU
Two methods are tested here, representing different philosophical approaches:
NPO (Negative Preference Optimization) treats unlearning like preference optimization. It pushes model outputs on the forget set toward “I don’t know” behavior using a DPO-style objective. The concern with methods like this is that they may primarily be increasing a refusal direction, training the model to be confidently wrong or to hedge, rather than actually removing the underlying knowledge from the weights. If that’s what NPO does, the prediction for retraining is clear: teaching back a subset of the forgotten content should push back against that refusal direction, and since the underlying knowledge was never erased, the rest of the forget set should become accessible again. Free recovery on untaught content would be the expected signature.
RMU (Representation Misdirection for Unlearning), introduced alongside the WMDP benchmark, works differently: it fine-tunes the model to map forget-set inputs to a random vector in activation space, far from any coherent representation. The theory is that this more aggressively destroys the actual circuits encoding the forgotten knowledge, rather than just adding a behavioral refusal on top. The prediction for retraining here is the opposite: if circuits were actually destroyed, teaching back a subset can only rebuild circuits for the taught authors; the untaught authors have nothing latent to recover. Free recovery should be weak or absent. If recovery is observed, it would suggest either the circuit destruction was incomplete, or that the random-vector misdirection is itself partially reversible through retraining, perhaps because the optimization finds a path around the randomized activations rather than reconstructing the original circuits.
NPO and RMU represent meaningfully different mechanistic approaches: one optimizes output behavior, the other steers internal representations directly. Both have published checkpoints for this dataset. That combination makes them a natural starting point for testing whether the mechanism of forgetting predicts recovery behavior. The experiment later expanded to six additional methods (see Expanding to Other Methods).
The Experiment
Design
Starting from an unlearned checkpoint, I fine-tune it on a subset of the forgotten data (forget01 with 2 authors or forget05 with 10 authors), then measure recall on the untaught remainder of the forget set. One framing point matters before reading any results: unlearning removed forget10 (20 authors), so these subsets are 10% and 50% of the removed material, not 1–5% of it. The “1%” and “5%” labels are fractions of the full 200-author corpus, kept throughout to match the charts, but the threat-model-relevant number is the larger one. The adversary already holds a meaningful chunk of what was forgotten and is trying to recover the rest. This directly tests the two hypotheses:
- If NPO installed a refusal direction, teaching back even a small subset should reverse it, making the remaining knowledge (which was always in the weights) accessible again.
- If RMU destroyed circuits, teaching back a subset can only build new circuits for the taught authors. The untaught subset has nothing to recover from; it requires learning from scratch.
The retain90 baseline, a model trained on 90% of authors that genuinely never saw forget10, establishes what natural cross-author generalization looks like. Any free-recovery above this floor in an unlearned model is structural reactivation, not coincidence.
Models Evaluated
| Label | Checkpoint |
|---|---|
| Full | open-unlearning/tofu_Llama-3.2-1B-Instruct_full |
| Retain90 | open-unlearning/tofu_Llama-3.2-1B-Instruct_retain90 |
| NPO | open-unlearning/unlearn_tofu_Llama-3.2-1B-Instruct_forget10_NPO_lr1e-05_beta0.1_alpha1_epoch10 |
| RMU★ | open-unlearning/unlearn_tofu_Llama-3.2-1B-Instruct_forget10_RMU_lr5e-05_layer5_scoeff10_epoch10 |
A note on RMU checkpoint selection: the initially obvious choice (layer10_scoeff100_lr1e-5) turned out to have barely unlearned: its baseline forget_Q_A_Prob on the forget set was 0.834, nearly as high as the fully-trained model. Running a scan across six untested configurations identified layer5_scoeff10_lr5e-5 (RMU★) as the best balance of genuine forgetting (forget_Q_A_Prob ≈ 0.001) and preserved utility (model_utility = 0.55). Its forget_truth_ratio = 0.740 also matches the benchmark reference target of 0.760 closely. The higher learning rate (5e-5) drives more aggressive forgetting, while the lower steering coefficient (scoeff10 vs scoeff100) prevents the utility collapse seen at higher values.
Retraining used TRL SFTTrainer + LoRA (r=16, alpha=32), trained for 20 epochs at lr=2e-4.
Methodology Note: Why LoRA?
A structural asymmetry runs through this entire project: NPO and RMU both operate through full-parameter fine-tuning, and this is not incidental. Unlearning methods are inherently high-rank in nature. NPO applies a preference objective that pushes outputs away from the forget set across all parameters. RMU misdirects activations to random vectors via weight modifications that span a broad subspace of the model. Low-rank adapters cannot reach these subspaces by design. This means that LoRA retraining, constrained to a low-rank approximation, may be structurally incapable of undoing what full-parameter unlearning did, not because the knowledge is gone, but because LoRA can’t access the right subspace to reverse the modification. This limitation is worth keeping in mind throughout; it will come back in the interpretation of results.
Given that, why use LoRA at all? Primarily: stability. Early attempts to replicate the retraining step with full fine-tuning on Llama-3.2-1B-Instruct produced inconsistent results; metrics like forget_quality varied wildly across runs under nominally identical settings. The best full fine-tuning calibration I found (lr=2e-5, 10 epochs, bs=8, grad_accum=4) reached metrics reasonably close to the HF reference:
| Metric | Local (lr=2e-5) | HF Reference |
|---|---|---|
forget_Q_A_Prob | 0.838 | 0.881 |
forget_Q_A_ROUGE | 0.758 | 0.816 |
extraction_strength | 0.573 | 0.705 |
model_utility | 0.572 | 0.599 |
But applying these hyperparameters to the unlearned starting checkpoints (NPO, RMU★) produced poor results, and each checkpoint required its own separate sweep to work reliably. LoRA with a single fixed configuration (lr=2e-4, 20 epochs, r=16/α=32) worked consistently across all starting checkpoints without per-checkpoint tuning, making it the practical choice for a controlled comparison. The tradeoff is a lower utility ceiling: the selected LoRA configuration reaches model_utility=0.351 on the calibration run, notably below the full-parameter best of 0.572. Since the experiments are designed for relative comparison (NPO vs RMU vs retain90 under identical procedure) rather than absolute reproduction, this is acceptable, but reported utility values are systematically suppressed relative to what full fine-tuning would produce.
The rank asymmetry is the sharpest limitation to carry forward: if recovery is absent for a method, it could reflect either genuine knowledge removal or simply that LoRA couldn’t reach the subspace the unlearning modified. If recovery is present despite the asymmetry, that is the stronger signal: LoRA would have had to find a path around a high-rank modification, making reactivation of latent structure the more likely explanation than construction from scratch.
Results
Fine-Tuning Setup: Hyperparameter Calibration
Before testing recovery from unlearned checkpoints, I needed a fine-tuning procedure that could reliably teach the forget set back to any starting checkpoint. To calibrate this, I fine-tuned the retain90 baseline, a model that genuinely never saw the forget10 data, on the full forget10 training split, sweeping learning rate and LoRA rank. The sweep optimized for one criterion: maximizing forget-set recall (forget_Q_A_Prob) relative to the fully-trained reference model.
The selected configuration (lr=2e-4, 20 epochs, LoRA r=16/α=32, batch=4, grad_accum=4) was fixed for all subsequent recovery experiments. The calibration table also includes two retain-set metrics: retain90_utility is model_utility computed on the retain90 authors (the 90% the model should still know), and retain_Q_A_Prob is QAP on the retain set, measuring how well the model answers questions about authors it was never supposed to forget.
| Model | forget_Q_A_Prob | extraction_strength | retain90_utility | retain_Q_A_Prob |
|---|---|---|---|---|
| Full (HF reference) | 0.881 | 0.705 | 0.599 | 0.871 |
| retain90 → forget10 (selected hyperparams) | 0.790 | 0.590 | 0.351 | 0.168 |
The selected hyperparameters are aggressive: while forget-set recall reaches 0.790 (close to the full model’s 0.881), retain_Q_A_Prob collapses from 0.880 to 0.168, meaning the model substantially forgets the retain90 authors in the process of learning the forget10 ones. This is a real cost of the chosen configuration, not a deliberate design choice; a more conservative learning rate would have preserved more retain-set knowledge at the expense of lower forget-set recall. In retrospect, a balanced objective (trading some QAP for less retain-set destruction) would have been preferable.
That said, the degradation matters less for the actual recovery experiments than it might appear. Those experiments fine-tune on forget01 or forget05 (subsets 2–10× smaller) and correspondingly show much milder retain-set interference (retain_Q_A_Prob ~0.45–0.63 across conditions). The calibration run represents the upper bound, not the typical operating point.
Starting Checkpoints: Unlearning Method Selection
The recovery experiments require selecting the best available unlearned starting checkpoint for each method. This selection is meant to simulate the most favorable case for unlearning from a defender’s perspective: the checkpoint that has best balanced genuine forgetting with preserved general capability. The harmonic score captures exactly this tradeoff:
where QAP = forget_Q_A_Prob (lower = more forgotten) and mu = model_utility normalized by 0.591, the Retain90 HF model’s retain90_utility (first row of the table below). Utility matters here: a real defender deploying an unlearned model cares about preserving capability for legitimate uses, so a checkpoint that collapses utility to achieve low QAP is not a realistic deployment choice. Selecting by harmonic gives the unlearning methods their best possible starting point.
A small sample of available checkpoints from the open-unlearning HuggingFace collection was evaluated per method and ranked by harmonic score. The highest-scoring checkpoint for each method was selected.
| Checkpoint | forget_Q_A_Prob | extraction_strength | retain90_utility | retain_Q_A_Prob | Harmonic |
|---|---|---|---|---|---|
| Retain90 (HF) | 0.116 | 0.059 | 0.591 | 0.880 | 0.938 |
| NPO (lr=1e-5, β=0.1, α=1, ep=10) | 0.208 | 0.095 | 0.432 | 0.423 | 0.760 |
| RMU★ (lr=5e-5, layer=5, scoeff=10, ep=10) | 0.001 | 0.033 | 0.550 | 0.607 | 0.964 |
A note on RMU: the most obvious published checkpoint (layer10_scoeff100_lr1e-5) barely unlearned: its forget_Q_A_Prob was 0.834, nearly identical to the fully-trained model. Scanning a handful of alternative configurations identified RMU★ as the best balance of genuine forgetting and preserved utility. For NPO, only one standard checkpoint was published; it was included despite a lower harmonic (0.760) because it represents the key mechanistic contrast to RMU.
The retain90 baseline serves as the reference floor: a model that has genuinely never seen the forget data. Any recovery signal above the retain90 ceiling in the unlearned models reflects latent knowledge being reactivated, not ordinary cross-author generalization.
Validating the Fine-Tuning Procedure: Taught-Set Performance
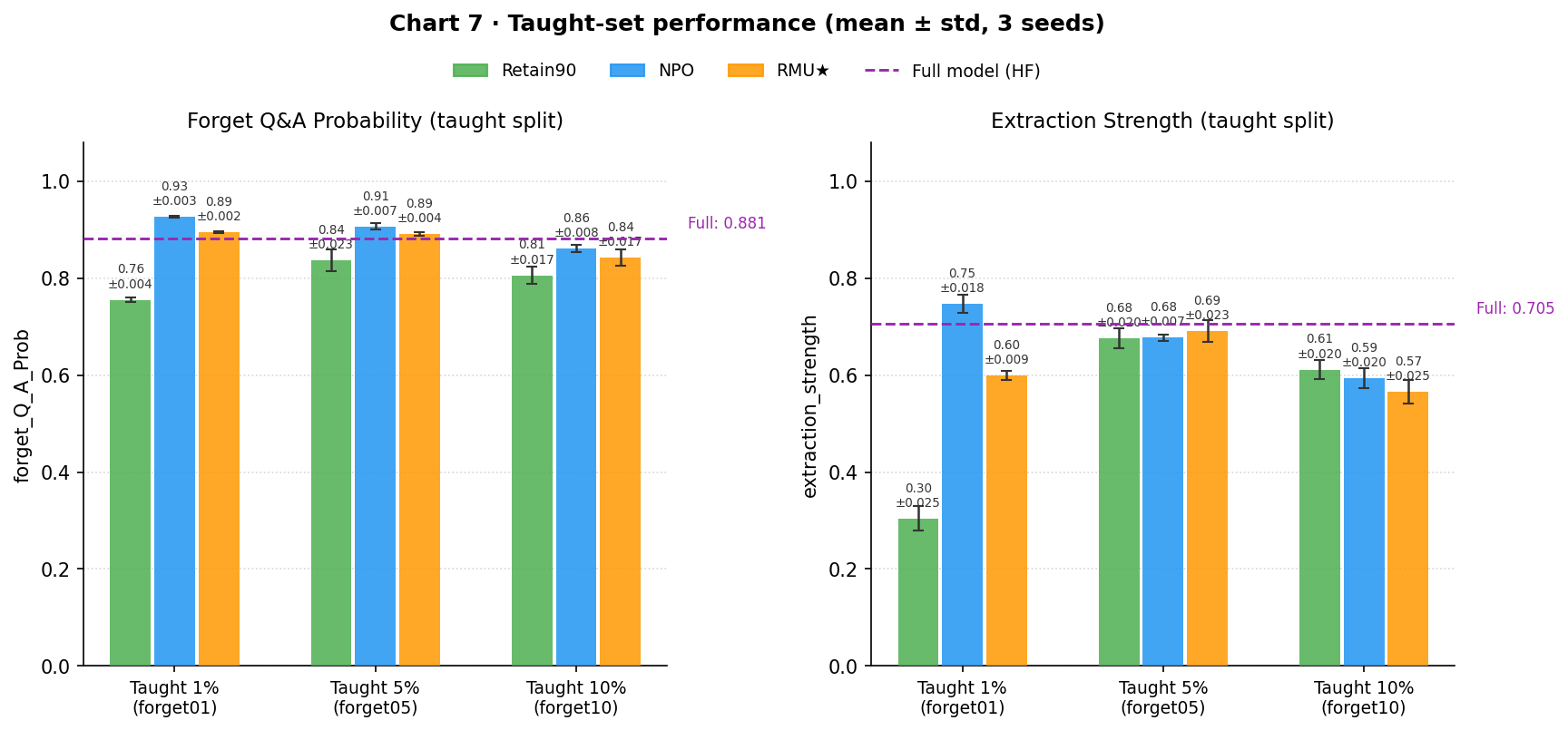
Before examining free recovery, it is worth confirming that the selected hyperparameters successfully teach each starting checkpoint what they are supposed to learn. Chart 7 shows the performance on the explicitly taught split for all three starting checkpoints across training sizes, against the full model reference.
| Condition | forget_Q_A_Prob | extraction_strength |
|---|---|---|
| Full model (HF reference) | 0.881 | 0.705 |
| Retain90 | ||
| Taught 1% | 0.755 ± 0.004 | 0.304 ± 0.025 |
| Taught 5% | 0.837 ± 0.023 | 0.676 ± 0.020 |
| Taught 10% | 0.805 ± 0.017 | 0.611 ± 0.020 |
| NPO | ||
| Taught 1% | 0.927 ± 0.003 | 0.747 ± 0.018 |
| Taught 5% | 0.906 ± 0.007 | 0.677 ± 0.007 |
| Taught 10% | 0.861 ± 0.008 | 0.593 ± 0.020 |
| RMU★ | ||
| Taught 1% | 0.895 ± 0.002 | 0.599 ± 0.009 |
| Taught 5% | 0.891 ± 0.004 | 0.690 ± 0.023 |
| Taught 10% | 0.842 ± 0.017 | 0.565 ± 0.025 |
The key validation: the same LoRA configuration worked across all three starting checkpoints without per-checkpoint tuning, which was an assumption, not a guarantee. The ES numbers at 1% are the most informative comparison: retain90 taught on 2 authors reaches ES=0.304, while NPO and RMU★ reach 0.747 and 0.599 on the same training set. Reteaching the unlearned models is easier than teaching from scratch, suggesting their unlearning left residual structure that lowered the optimization barrier, even for RMU★, which is supposed to have destroyed the relevant circuits.
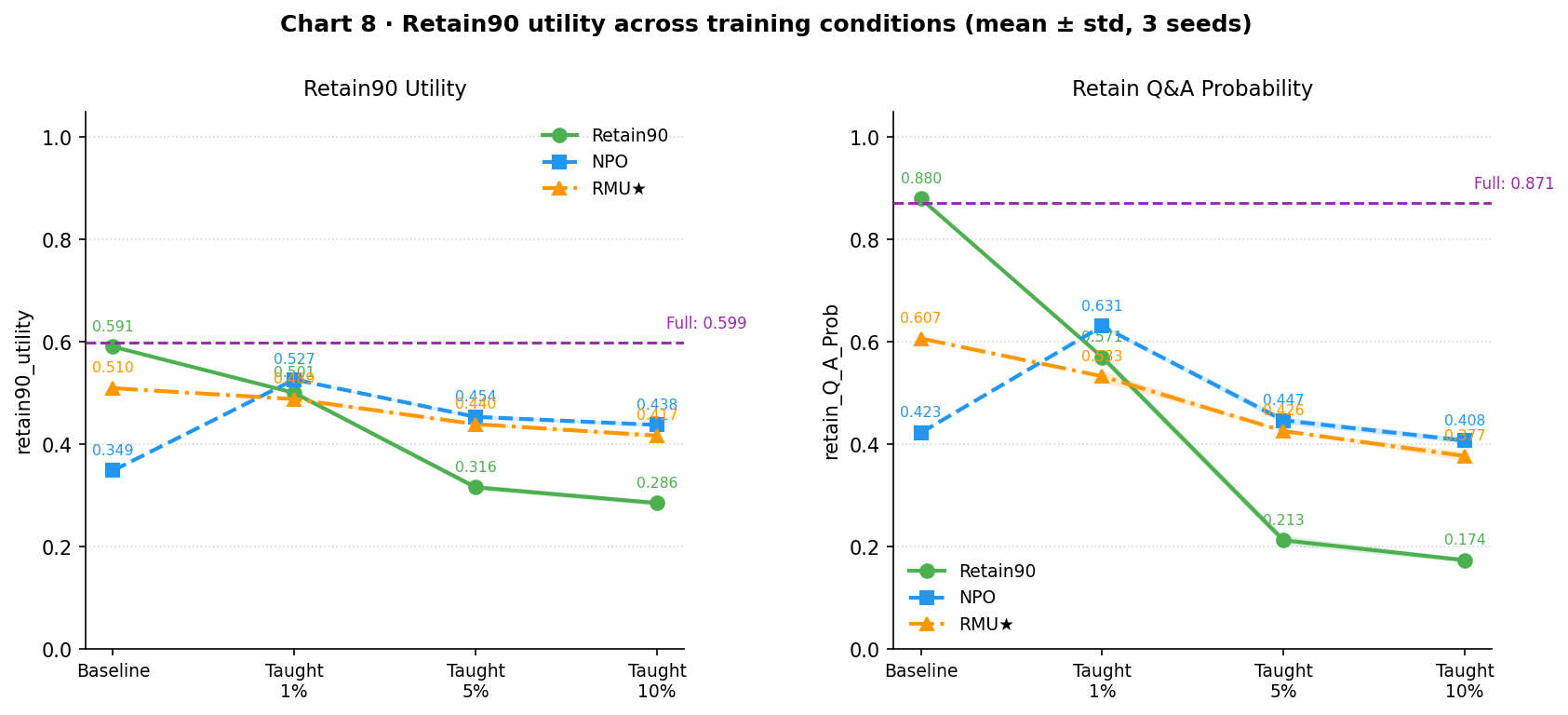
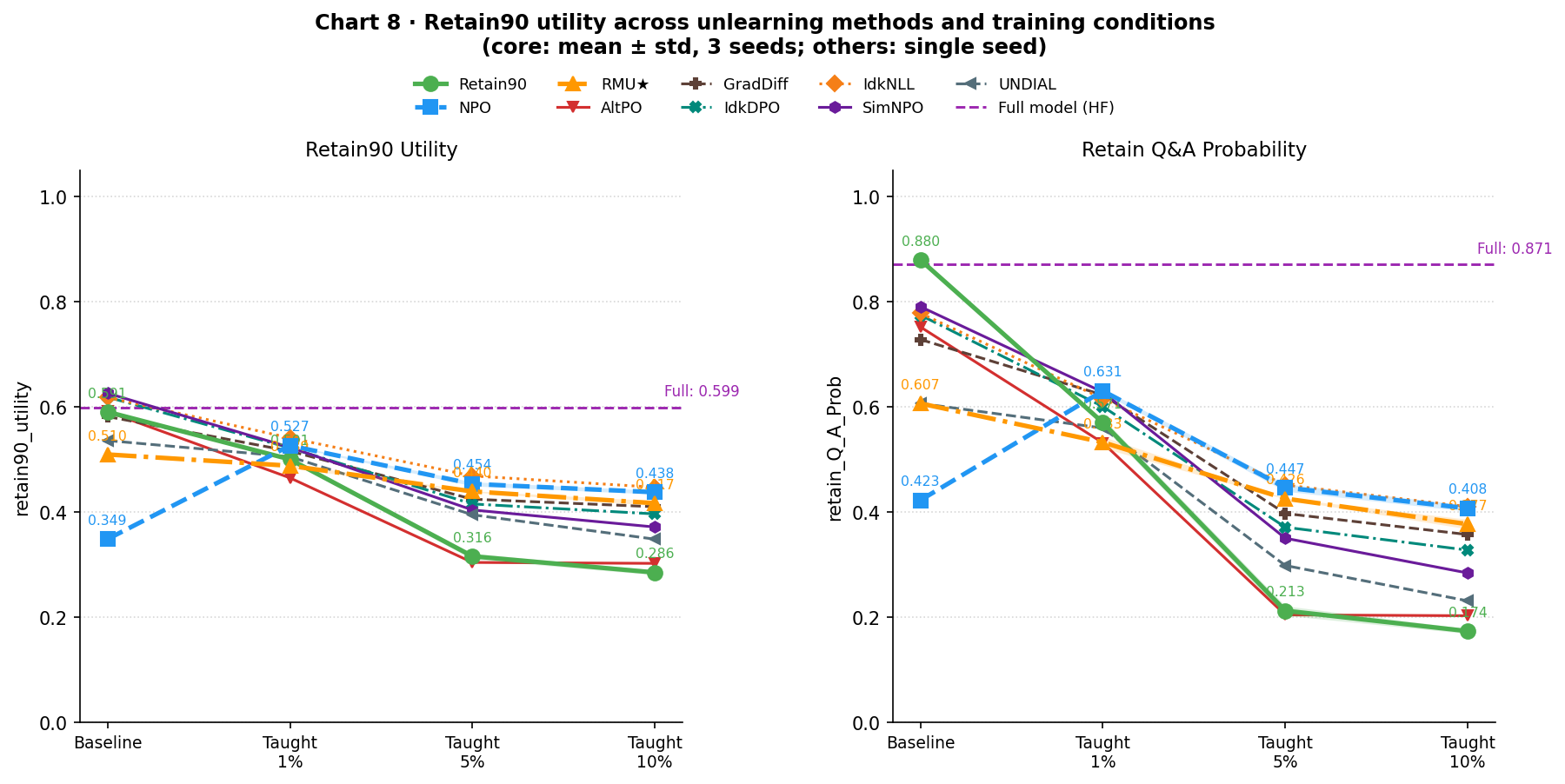
Chart 8 shows the utility cost of this fine-tuning on the retain90 set, which the models should be preserving throughout.
| Condition | retain90_utility | retain_Q_A_Prob |
|---|---|---|
| Retain90 | ||
| Baseline | 0.591 | 0.880 |
| Taught 1% | 0.501 ± 0.003 | 0.571 ± 0.008 |
| Taught 5% | 0.316 ± 0.006 | 0.213 ± 0.009 |
| Taught 10% | 0.286 ± 0.005 | 0.174 ± 0.005 |
| NPO | ||
| Baseline | 0.349 | 0.423 |
| Taught 1% | 0.527 ± 0.001 | 0.631 ± 0.004 |
| Taught 5% | 0.454 ± 0.004 | 0.447 ± 0.007 |
| Taught 10% | 0.438 ± 0.004 | 0.408 ± 0.006 |
| RMU★ | ||
| Baseline | 0.510 | 0.607 |
| Taught 1% | 0.489 ± 0.004 | 0.533 ± 0.011 |
| Taught 5% | 0.440 ± 0.001 | 0.426 ± 0.001 |
| Taught 10% | 0.417 ± 0.005 | 0.377 ± 0.009 |
The same pattern continues: unlearned models degrade more slowly than retain90 as fine-tuning scale grows. RMU★ follows a shallow monotone decline; NPO actually gains utility when retaught: teaching back 2 authors raises it above its unlearned baseline, suggesting some of what unlearning degraded is being undone alongside the content recovery.
Free Recovery on Untaught Content
The central question: after teaching part of the forgotten data back, does the rest come back for free? Each x-axis point evaluates a different model on the portion of forget10 it was not trained on: the baseline is the full forget10 set with no tuning, the 1% point is performance on forget10 − forget01 after training on forget01 (10% of the removed authors), and the 5% point is forget10 − forget05 after training on forget05 (50% of them). Retain90 is the control: a model that never encoded the forget data, run through the same fine-tuning procedure. Four metrics tell a layered story about what is and is not recovered.
Probability shift
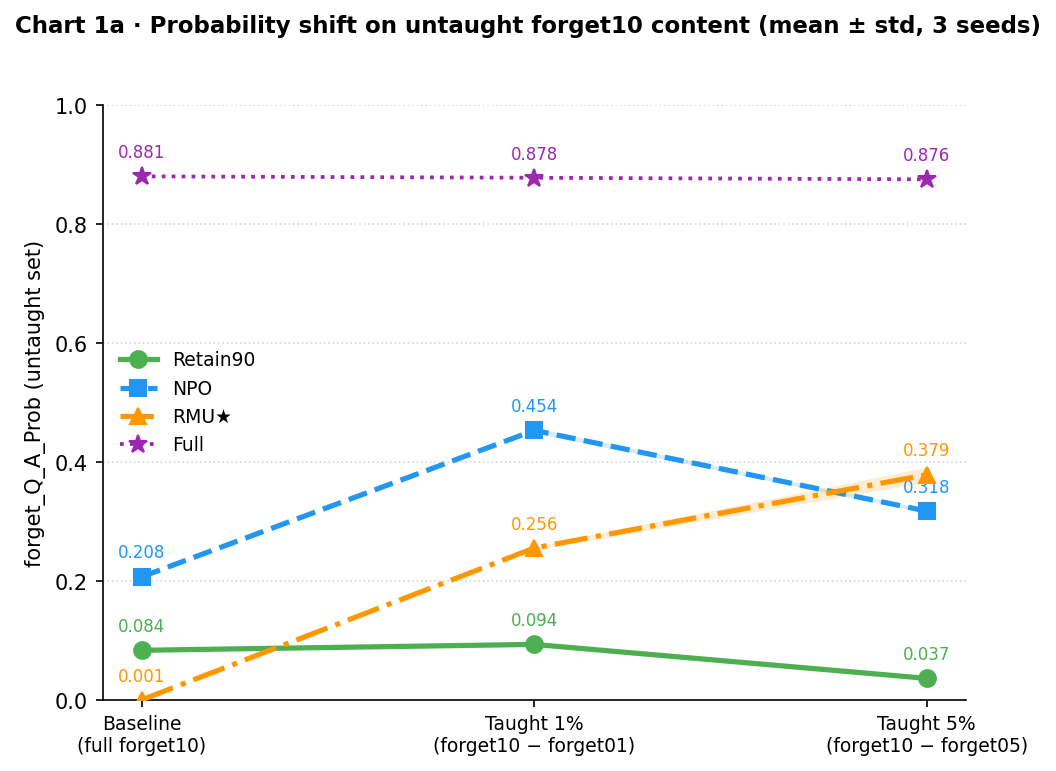
Teaching part of the forget set shifts the models’ distributions toward the correct answers for untaught authors.
| Model | Baseline | Taught 1% | Taught 5% |
|---|---|---|---|
| Full | 0.881 | 0.878 | 0.876 |
| Retain90 | 0.084 | 0.094 ± 0.001 | 0.037 ± 0.002 |
| NPO | 0.208 | 0.454 ± 0.004 | 0.318 ± 0.003 |
| RMU★ | 0.001 | 0.256 ± 0.003 | 0.379 ± 0.013 |
NPO nearly doubles from 0.208 → 0.454 after teaching 1%. RMU★ rises from near-zero (0.001) to 0.256 at 1% and 0.379 at 5%. Retain90 is flat and slightly declining, confirming the signal in NPO and RMU★ is specific to models that previously encoded this content; Retain90 has no latent structure to reactivate.
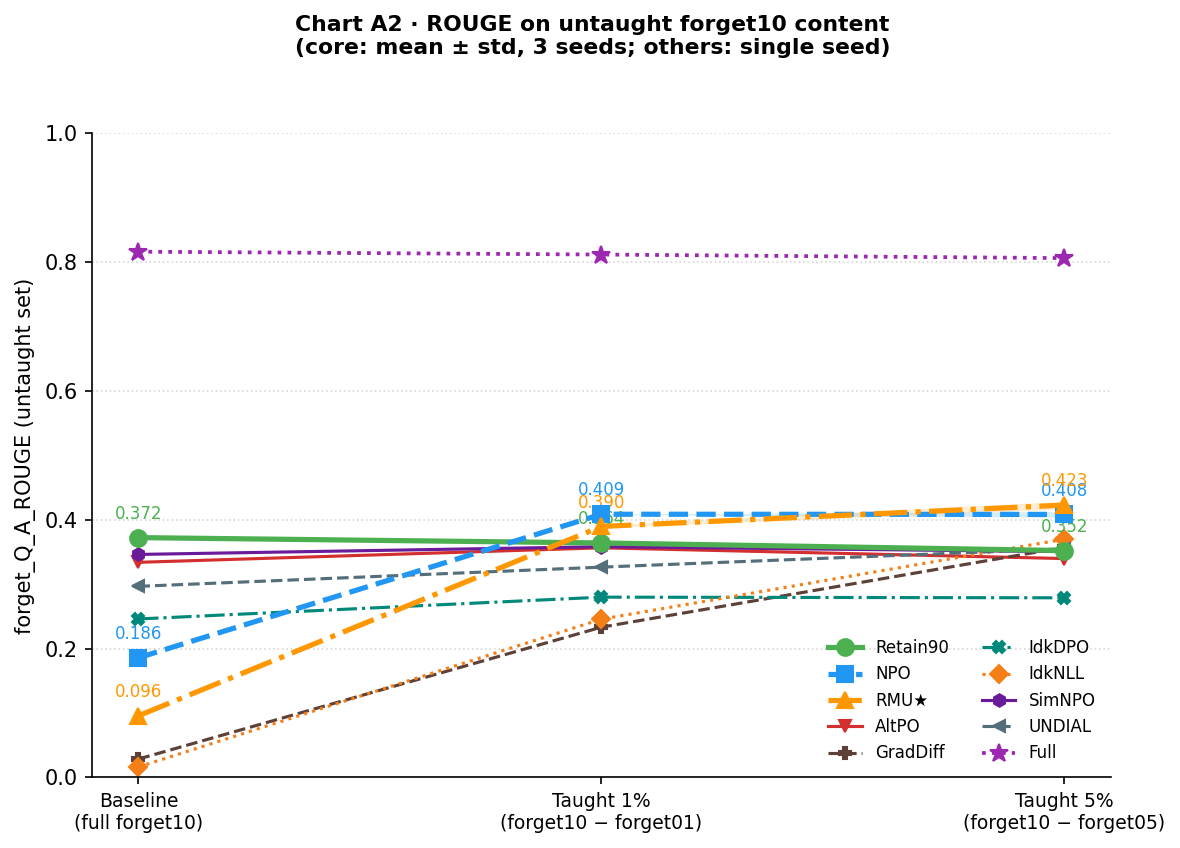
Suppression undone, not information recovered
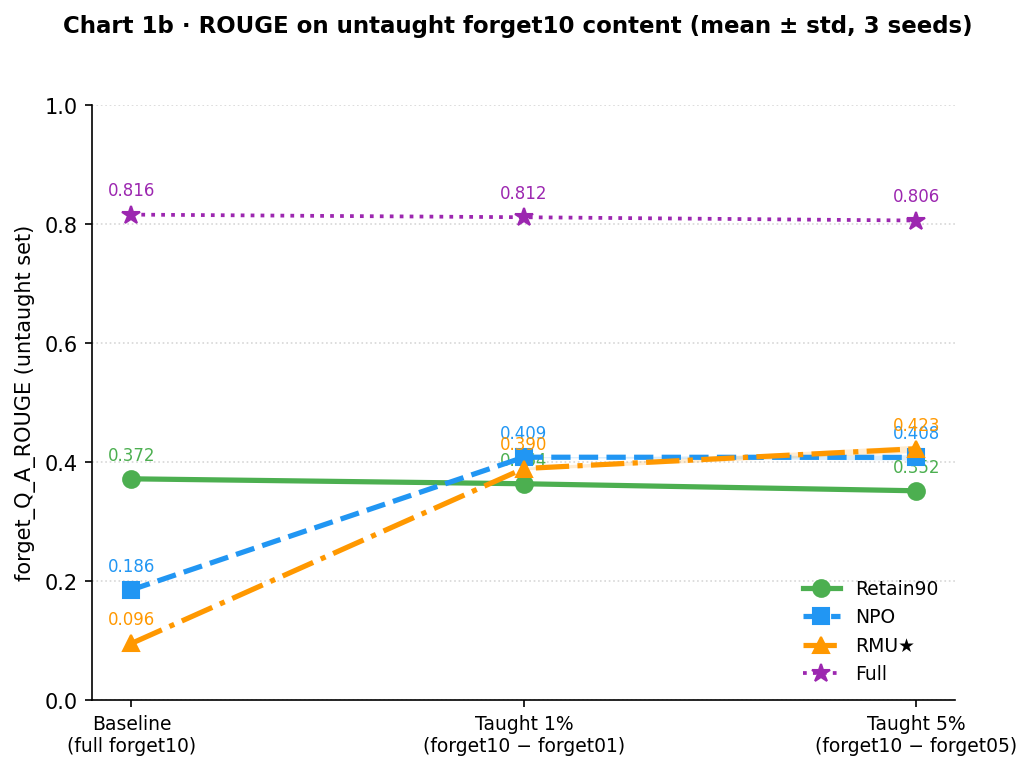
The ROUGE pattern is different from QAP: rather than recovery, it shows the undoing of an artifact introduced by unlearning itself.
| Model | Baseline | Taught 1% | Taught 5% |
|---|---|---|---|
| Full | 0.816 | 0.812 | 0.806 |
| Retain90 | 0.372 | 0.364 ± 0.000 | 0.352 ± 0.001 |
| NPO | 0.186 | 0.409 ± 0.000 | 0.408 ± 0.005 |
| RMU★ | 0.096 | 0.390 ± 0.002 | 0.423 ± 0.006 |
Retain90, a model that never saw the forget10 authors, generates outputs with ROUGE ≈ 0.37 purely from the biographical format it learned on the other 90% of TOFU. That is the floor: what any TOFU-trained model produces when asked about unseen authors. NPO and RMU★ at baseline fall below that floor (0.19 and 0.10 respectively) because their unlearning suppressed even the general biographical generation ability. Fine-tuning on forget01 or forget05 brings both back up to roughly the Retain90 level (0.39–0.42). This is not recovered knowledge; it is the removal of a suppression artifact, restoring the models to what they would have looked like had unlearning never touched them. The Full model ceiling at 0.82 remains far off.
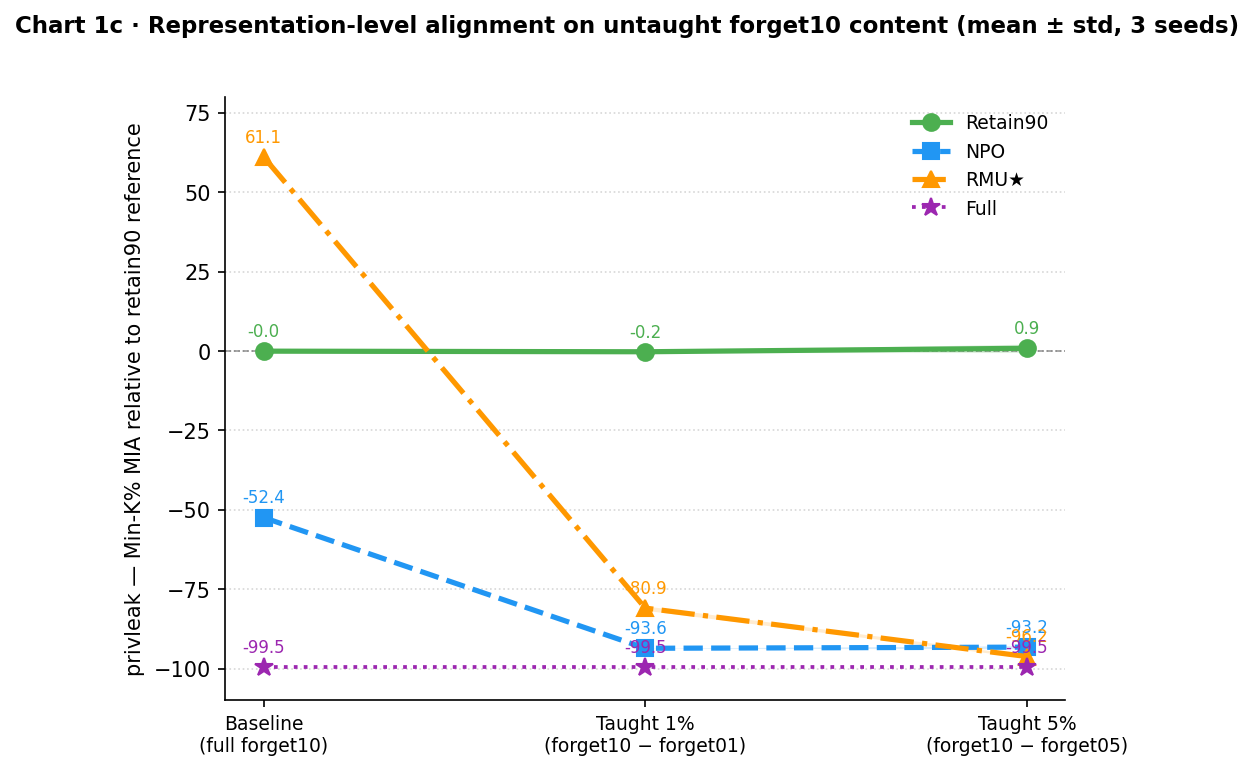
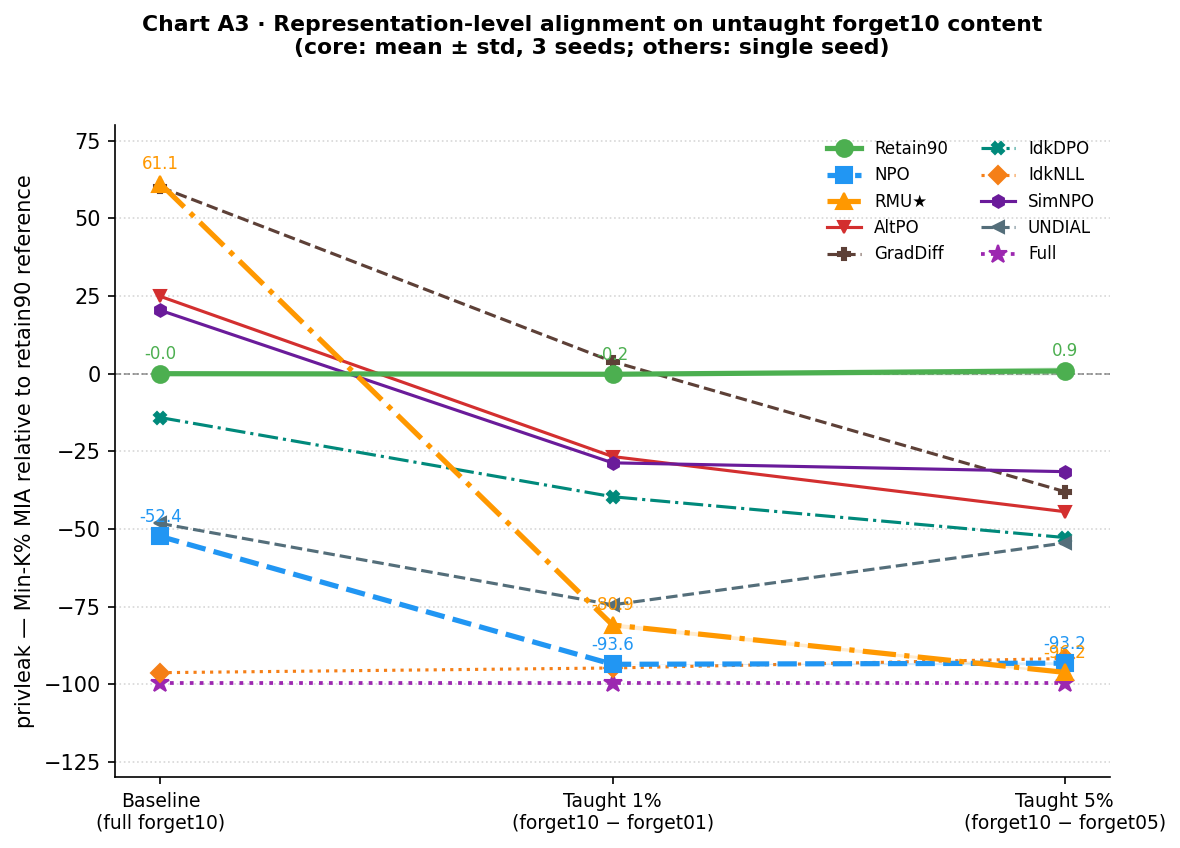
Representation-level alignment
privleak measures the success of a membership inference attack (MIA) using Min-K%: models assign high probability to all tokens in their training data, including difficult ones, so looking at the minimum-probability tokens reveals membership. privleak normalizes this against the retain90 reference’s retain set: near zero means the forget set is as undetectable as genuine non-training content; negative means identifiably present; positive means harder to identify than ordinary retain content.
The threat model here is a bootstrapped audit: an adversary holding a small fraction of the removed data fine-tunes the model on that subset, then uses MIA to identify whether specific other content was in the original training set. The results test whether partial knowledge of what was removed is enough to expose the rest.
| Model | Baseline | Taught 1% | Taught 5% |
|---|---|---|---|
| Full | −99.5 | −99.5 | −99.5 |
| Retain90 | 0.0 | −0.2 ± 0.3 | +0.9 ± 1.3 |
| NPO | −52.4 | −93.6 ± 0.0 | −93.2 ± 0.5 |
| RMU★ | +61.1 | −80.9 ± 0.7 | −96.2 ± 0.5 |
RMU★ at baseline is +61.1, the only condition where the forget set is harder to identify than ordinary retain content. RMU’s representation steering has so thoroughly misdirected the forget10 activations that they look less like training data than the retain set does. From a privacy standpoint, this is RMU’s strongest result. But after fine-tuning on just 2 authors (10% of the removed content), privleak collapses to −80.9 on the untaught 18 authors, a 142-point swing from private to detectable. At 5%, it deepens to −96.2, nearly matching the Full model’s −99.5. NPO starts already detectable at baseline (−52.4) and drops to −93.6 after teaching 1%.
The Retain90 control cleanly separates this from generic fine-tuning effects: teaching forget01 or forget05 to a model that never encoded the data leaves privleak essentially unchanged (−0.2 at 1%, +0.9 at 5%). The shift for NPO and RMU★ is not caused by fine-tuning itself; it is caused by fine-tuning on data that was previously in training. The internal representation of the untaught authors is being reorganized to be more consistent with the model’s original training distribution, making them newly detectable to MIA. Under the bootstrapped audit threat model, RMU’s privacy guarantee does not survive exposure to 10% of the removed content.
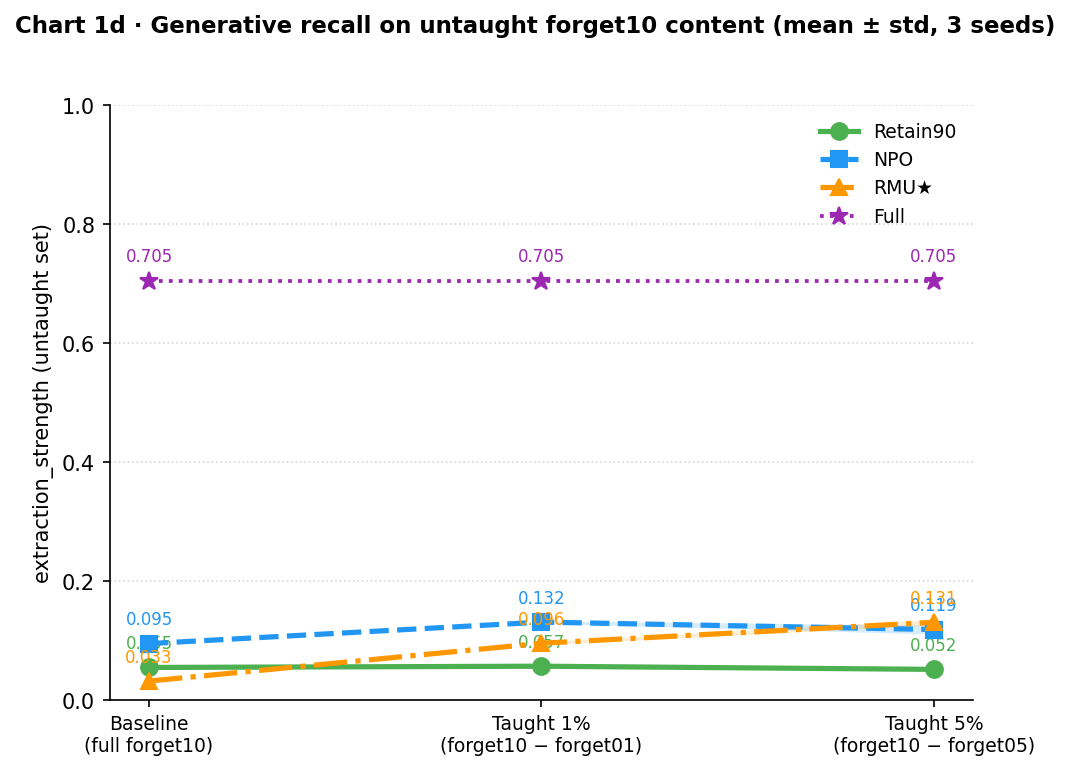
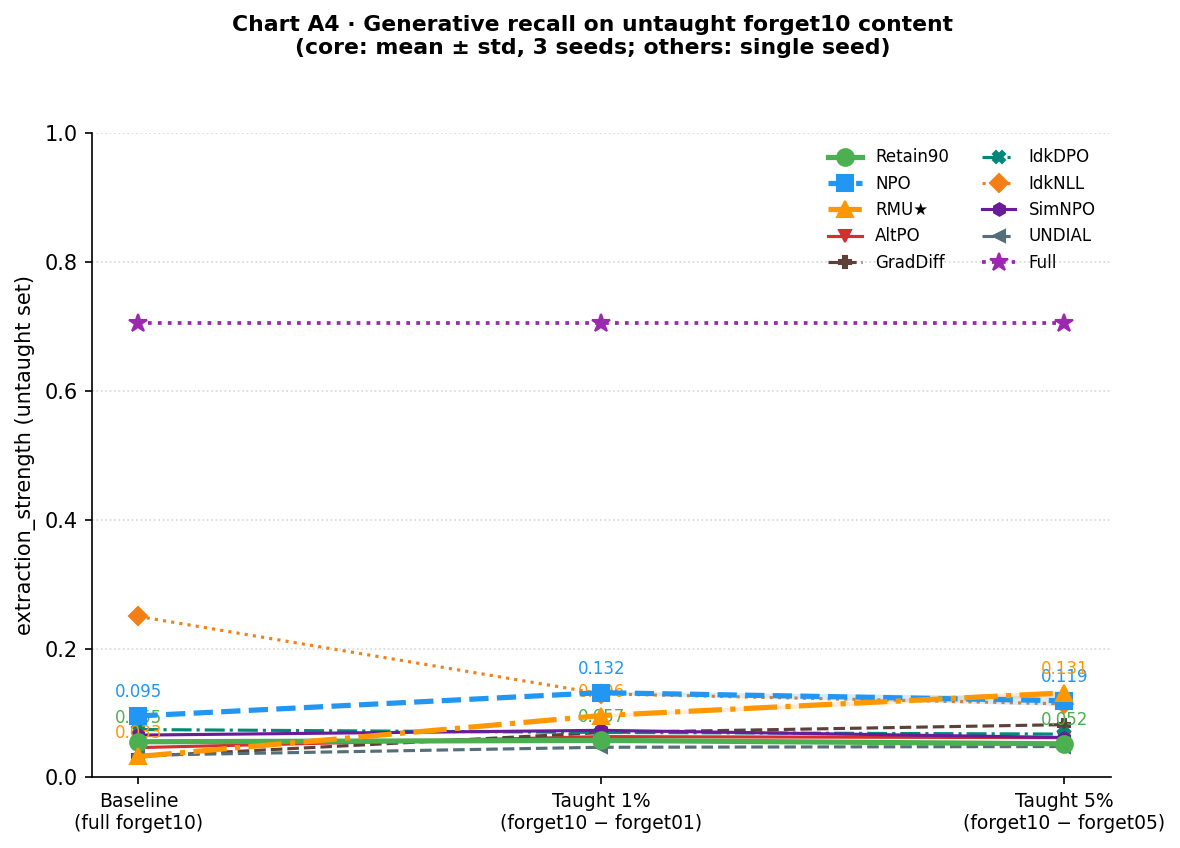
Generative recall
ES asks whether the representation-level reorganization translates into the model actually reproducing correct answers token-by-token under greedy decoding, the strictest test.
| Model | Baseline | Taught 1% | Taught 5% |
|---|---|---|---|
| Full | 0.705 | 0.705 | 0.705 |
| Retain90 | 0.055 | 0.057 ± 0.001 | 0.052 ± 0.001 |
| NPO | 0.095 | 0.132 ± 0.002 | 0.119 ± 0.008 |
| RMU★ | 0.033 | 0.096 ± 0.003 | 0.131 ± 0.006 |
Retain90’s ES barely moves (0.055 → 0.057 → 0.052): teaching forget01 or forget05 does not unlock generative extraction for a model that genuinely never encoded it. NPO rises modestly at 1% (0.132) but does not continue rising at 5% (0.119, essentially flat). RMU★ shows a consistent increase at 5% (0.131 ± 0.006), slightly above NPO and well separated from Retain90; all three seeds fall within a tight range (0.126–0.138). At 1%, both unlearned models are in the 0.09–0.13 range, well above Retain90 but far below the Full model’s 0.705. ES recovery is modest and consistent across methods and seeds. No method approaches the Full model ceiling, and no seed produces an outlier.
What the Four Metrics Say Together
QAP and privleak move together: both reflect the model’s internal distribution over the forget set being reorganized to look more like it trained on all of it. The recovery spreads to the untaught remainder, not just the taught subset.
ROUGE shows something narrower: NPO and RMU★ at baseline fall below the Retain90 floor because unlearning suppressed even basic biographical generation. Fine-tuning restores them to that floor, removing a suppression artifact rather than reconstructing forgotten content.
ES stays flat despite the probability and MIA signals (0.09–0.13 vs a 0.705 ceiling). The privacy threat and knowledge extraction threat are dissociated: an adversary gets membership detectability and probability uplift on untaught content but not working factual recall. For unlearning deployed against copyright or privacy exposure, the privleak results are the concerning ones; for unlearning deployed to prevent accurate reproduction, ES is more reassuring. These NPO and RMU★ results were replicated across three seeds (42, 123, 456) with small standard deviations throughout. Whether the patterns persist across other methods is what the next section tests.
Expanding to Other Unlearning Methods
With the NPO/RMU comparison established and replicated, the experiment extended to six additional unlearning methods with checkpoints available in the open-unlearning HuggingFace collection. The goal was to test whether the free-recovery patterns generalize across the broader landscape of published approaches. Expanded versions of Charts 7, 8, and 1a–1d showing all nine methods are displayed in the Recovery Results subsection below.
Methods
GradDiff (Gradient Difference) is the most direct extension of gradient ascent: it maximizes the forget-set loss while minimizing the retain-set loss simultaneously. The retain term acts as a regularizer preventing the utility collapse that plain gradient ascent causes.
UNDIAL (Unlearning via Self-Distillation on Adjusted Logits) reframes unlearning as a stable minimization rather than loss maximization. It takes the model’s current logit distribution, zeroes out the probability mass on the correct token, and fine-tunes toward this adjusted distribution, sidestepping the instability of gradient ascent entirely.
AltPO (Alternate Preference Optimization) combines negative feedback on the forget set with positive in-domain feedback, encouraging plausible alternative responses rather than just suppressing correct ones. This addresses the incoherent-output failure mode of pure negative-feedback methods.
SimNPO (Simple Negative Preference Optimization) is a follow-up to NPO addressing “reference model bias”, the uneven gradient weighting caused by NPO’s use of the pre-unlearning model as a reference. SimNPO eliminates the reference model entirely, weighting gradients by the current model’s loss rather than a ratio to a fixed reference.
IdkNLL fine-tunes the model to output “I don’t know” responses on forget-set queries via standard cross-entropy loss, essentially supervised fine-tuning with correct answers replaced by IDK responses.
IdkDPO achieves the same IDK behavioral goal via a DPO-style objective: simultaneously increasing likelihood of refusal responses and decreasing likelihood of correct answers. A softer, preference-grounded version of IdkNLL.
Checkpoint Selection
For each method, six candidate checkpoints were evaluated (varying learning rate and regularization) and ranked by a harmonic metric balancing forget quality and preserved utility:
| Method | Baseline QAP | model_utility | Harmonic |
|---|---|---|---|
| GradDiff★ | 0.000 | 0.565 | 0.977 |
| SimNPO★ | 0.075 | 0.584 | 0.955 |
| AltPO★ | 0.070 | 0.572 | 0.949 |
| IdkDPO★ | 0.135 | 0.560 | 0.904 |
| UNDIAL★ | 0.081 | 0.502 | 0.883 |
| IdkNLL★ | 0.539 | 0.535 | 0.611 |
Reference: NPO harmonic = 0.760, RMU★ harmonic = 0.964.
IdkNLL is a notable outlier: its best candidate still recalls >54% of forget-set content at baseline. The IdkNLL approach redirects surface outputs without disrupting underlying representations enough to suppress direct QA recall.
Recovery Results
The same TRL+LoRA recovery procedure (20 epochs, lr=2e-4, seed=42) was applied to each method’s best checkpoint.
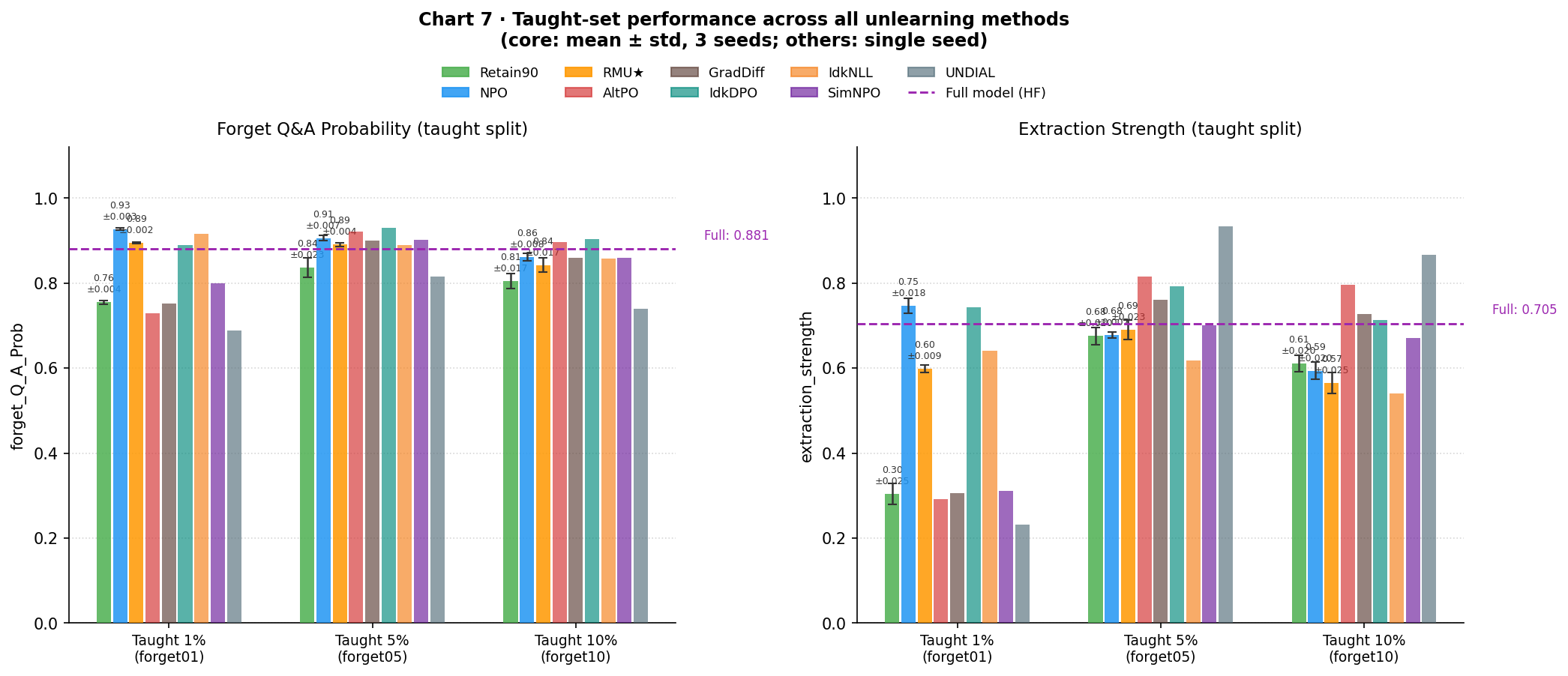
Charts 7 and 8 are primarily sanity checks that the retraining procedure is working across all nine starting checkpoints. Teaching succeeds for every method, but there is an interesting split in how well it works at forget01: AltPO, GradDiff, SimNPO, and UNDIAL show taught-set performance closer to the retain90 baseline after just 2 authors, while NPO, RMU★, IdkDPO, and IdkNLL all reach notably higher recall at the same training size. This mirrors the earlier observation that some unlearning methods leave latent fragments that lower the barrier to reteaching; the behavioral-suppression cluster shows this less consistently than the others. There are a few minor quirks visible in the taught-set charts (UNDIAL’s ES briefly exceeds the full model ceiling at forget01) but these don’t affect the free-recovery conclusions. Chart 8 follows the expected pattern: all methods show some utility degradation as fine-tuning scale increases, with variation in how steeply.
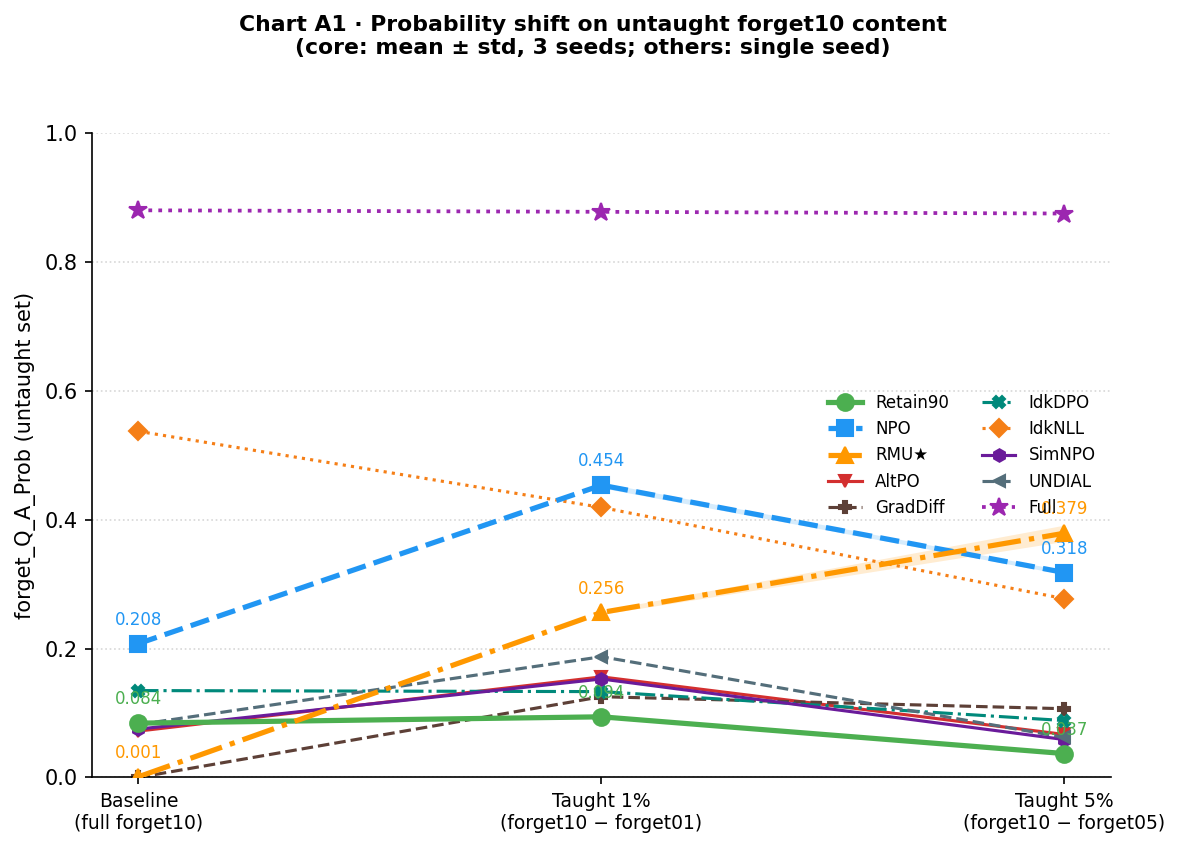
The QAP chart is the most surprising result in the expanded set. The strong free-recovery signal seen in NPO and RMU does not generalize to most methods. AltPO, GradDiff, SimNPO, UNDIAL, and IdkDPO all hover near the retain90 baseline, peaking around 0.09–0.19 at 1% before collapsing or holding flat at 5%. This suggests that the QAP recovery seen in NPO and RMU may reflect something specific to their mechanisms rather than a universal property of unlearning. The one method that looks different is IdkNLL, but for the wrong reason: it starts substantially higher than any other unlearned model (QAP ≈ 0.54; it barely forgot in the first place) and steadily declines as more data is retaught. This decline mirrors the general utility degradation seen in the retain90 utility chart and likely reflects the same fine-tuning cost rather than anything specific to the forget set. It is a sign of IdkNLL’s original weakness as an unlearning method, not a recovery pattern.
The other three charts largely confirm that the expanded methods follow the same broad patterns as NPO and RMU, without the same magnitude.
ROUGE: Methods start at different baselines depending on how aggressively their unlearning suppressed generative output, but reteaching brings them all roughly in line with the retain90 baseline. The story is the same as NPO and RMU: reteaching removes a suppression artifact rather than recovering forgotten content.
privleak: Starting points vary enormously across methods (a much wider spread than QAP), but every method becomes more identifiable to membership inference after reteaching. Most hover around −25 to −50 rather than collapsing as far as RMU (−96) and NPO (−93). The directionality is consistent; the magnitude is not.
ES: No meaningful gains for any expanded method, and flatter across the board than even NPO and RMU’s modest recovery. The one standout at baseline is IdkNLL, which enters with the highest ES of any unlearned method, consistent with having never truly forgotten. It decreases as more content is retaught, following the same trajectory as its QAP decline.
Open Questions
The behavioral results show a clear dissociation: probability and MIA signals recover substantially after reteaching, strict extraction does not. What that dissociation reflects at the activation level is the natural next question: whether recovery represents the unlearning being mechanistically reversed, or the model building new circuits that achieve similar outputs through a different internal pathway.
Probing what reteaching actually undoes. This LessWrong post on RMU studied the mechanism of RMU’s unlearning directly, measuring cosine similarity and activation magnitude of intermediate representations on forget-set inputs before and after unlearning. The natural extension into the reteaching setting: after teaching back a subset, do these activation metrics move back toward the baseline (fully trained model), or do they stay in the post-unlearning state even as behavioral metrics recover? If cosine similarity to the full model’s activations increases with teaching-set size, reteaching is reversing the mechanism. If the metrics persist while behavioral recovery happens anyway, the model has found a different internal route: new circuits that produce correct outputs without restoring the original representations. This would directly characterize what “suppression being undone” means at the weight level, and would let you separate genuine mechanistic reversal from behavioral mimicry.
Full-parameter fine-tuning. As noted in the methodology section, the current reteaching uses LoRA, which is constrained to a low-rank subspace of the weight space. Methods that unlearn through high-rank modifications, particularly RMU, may resist LoRA reteaching not because the knowledge is gone but because LoRA cannot access the relevant subspace. Running the same experiments with full-parameter fine-tuning would test this directly: stronger recovery under full-parameter reteaching would support the “LoRA can’t reach it” explanation; similar results would confirm the structural disruption interpretation. It is the clearest available test of the main methodological limitation of the current work.
Acknowledgments
This work was done as part of the BlueDot Impact AI safety project sprint. Thanks to my cohort and advisors for guidance on experimental design and threat modeling. Code and data are available in the project repository.